 |
|
|
|
|
|
 |
 |
Neues aus der Welt der Wissenschaft |
|
|
|
|
|
|
Software lernt Englisch, Chinesisch und "Proteinisch" |
|
| | | Forscher aus Israel und den USA haben ein Computerprogramm entwickelt, das die Grammatik diverser Sprachen lernen kann. Das Programm kommt weitgehend ohne Lehrer aus, denn es bildet die grammatischen Regeln anhand von statistischen Mustern, die es vorher aus Texten abgeleitet hat. |
|
|
|
|
|
|
|
|
| |
Wie ein Team um Shimon Edelman von der Cornell University berichtet, funktioniert das Programm nicht nur bei natürlichen und künstlichen Sprachen, sondern prinzipiell bei allen nicht-zufälligen Symbolfolgen. Also etwa auch bei Sequenzdaten aus der Biologie.
|
|
Die Studie "Unsupervised learning of natural languages" von Zach Solan et al. erscheint im Fachjournal "Proceedings of the National Academy of Sciences" (doi: 10.1073_pnas.0409746102). |
|
|
 Zur Studie (sobald online) Zur Studie (sobald online) |
|
|
|
|
|
|
Noam Chomsky: Sorry, no statistics |
|
| |
"Colorless green ideas sleep furiously." Dieser Satz ist zwar offensichtlich sinnlos, trotzdem fällt es uns ziemlich leicht, ihn als grammatikalisch korrekt zu erkennen. Ganz im Gegensatz etwa zu: "Ideas colorless sleep furiously green."
Wie Noam Chomsky 1957 in seinem Buch "Syntactic Structures" hinwies, können wir nur beim ersten Satz in kürzester Zeit ein Urteil über dessen so genannte Wohlgeformtheit abgeben, obwohl beide - sinnlosen - Wortfolgen gleich unwahrscheinlich sind. So unwahrscheinlich nämlich, dass wir vermutlich nie in unserem Leben mit ihnen konfrontiert wurden.
Chomskys Schluss daraus: Die statistischen Eigenschaften der Sprache spielen für den natürlichen Spracherwerb bestenfalls eine untergeordnete Rolle, entscheidend sind angeborene grammatische Strukturen und logisches Denken.
|
|
|
|
|
|
Programm lernt ohne Lehrer |
|
| |
Neuere Forschungen zeigen allerdings, dass neben Regeln sehr wohl statistische Informationen für Erwerb und Gebrauch der Sprache wichtig sind (Science 298, 553).
Das gilt nicht nur für Menschen, sondern auch für Programme, mit deren Hilfe Computer Sprachen erlernen sollen. Ein aktuelles Beispiel dafür ist das Programm ADIOS ("automatic distillation of structure"), die von einem Team um den Psychologen Shimon Edelman entwickelt wurde.
Das Besondere daran: Der Algorithmus muss nur mit Textproben gefüttert werden, dann setzt ein selbständiger Lernprozess ein, bei dem ADIOS statistische Muster aus den verwendeten Texten extrahiert und dann zu hierarchischen Regeln verallgemeinert.
|
|
|
|
|
|
Hierarchie von Klassen
|
|
| |
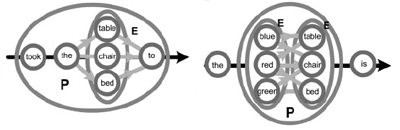
Edelman und Kollegen führen in ihrer Studie folgendes Beispiel an: ADIOS ist imstande, die Wörter "table", "chair" und "bed" in eine äquivalente Klasse einzuordnen, weil sie in gleichen Satzteilen an der selben Stelle auftreten. Diese Klasse verwendet das Programm, um weitere Klassen zu finden, etwa die Eigenschaftswörter "blue", "red" und green" (Bild oben).
Beide Gruppen können wiederum zu Klassen höherer Ordnung zusammengefasst werden, wodurch ein Baum von Regeln entsteht, der im Idealfall die korrekte Grammatik der verwendeten Sprache wiedergibt.
|
|
|
|
|
|
Trefferquote zwischen 70 und 100 Prozent |
|
| |
Die Forscher aus Israel und den USA testeten ihren sprachlichen Destillationsapparat, indem sie ihm unbekannte Sätze vorlegten und deren grammatikalische Korrektheit beurteilen oder selbst neue Sätze bilden ließen.
Am besten schnitt das Programm bei einfachen Kunstsprachen mit einer nahezu fehlerlosen Leistung ab, bei natürlichen Sprachen wie Englisch oder Chinesisch betrug die Trefferquote immerhin 70 Prozent.
|
|
|
|
|
|
Modell für den Spracherwerb |
|
| |
Edelman und Mitarbeiter sehen ihr Programm daher als brauchbares Modell für den menschlichen Spracherwerb, gestehen aber zu, dass dieses Modell notgedrungen unvollständig sein muss. Denn: Die Anbindung zu sprachlich vermittelten Handlungen (Stichwort: Sprechakte) und Ereignissen in der Außenwelt kann ADIOS freilich nicht erfassen.
|
|
|
|
|
|
Sprachferne Anwendung: Sequenzdaten |
|
| |
Interessant ist überdies, dass die Methode nicht nur bei Texten unterschiedlichster Provenienz (z.B. entwicklungspsychologische Textsammlungen, ausgewählte Stellen aus der Bibel) funktioniert, sondern auch bei ganz abstrakten Symbolfolgen.
Gemeint sind damit etwa Sequenzdaten von Proteinen aus der biologischen Grundlagenforschung. In diesem Fall sind die kleinsten analysierten Einheiten selbstverständlich keine Wörter, sondern die elementaren Bausteine der Eiweißkörper, die Aminosäuren.
Edelman und seine Kollegen untersuchten mehr als 6.500 Enzyme, die bereits zuvor aufgrund ihrer Funktion in verschiedene Familien klassifiziert wurden. Mit der "linguistischen" Methode lag die korrekte Einordnung bei rund 95 Prozent - und damit im Leistungsbereich anderer Bioinformatik-Programme, die sich auf die physikalischen Eigenschaften von Proteinen stützen.
Robert Czepel, science.ORF.at, 2.8.05
|
|
|
01.01.2010 |
