 |
|
|
|
|
|
 |
 |
Neues aus der Welt der Wissenschaft |
|
|
|
|
|
|
Internet: Gemeinschaftliches "Tagging" modelliert |
|
| | | Ob bei Lesezeichen, Blog-Einträgen, Fotos oder Videos - das gemeinschaftliche Indexieren oder "Collaborative Tagging" hat sich zu einem Schlüsselsystem entwickelt, wie Informationen effektiv organisiert und mit anderen Internet-Nutzern geteilt werden können. Italienische Wissenschaftler haben nun die Dynamik der Stichwortvergabe in einem Modell erfasst. |
|
|
|
|
|
|
|
|
| |
Das Verhalten der Nutzer, wie sie ihre Online-Informationen mit einem oder mehreren Begriffen kennzeichnen, hängt laut Ciro Cattuto von der Sapienza Universität in Rom und seinen Kollegen von zwei Aspekten ab: von dem Tagging-Verhalten anderer Personen sowie von Informationen zur Aktualität der Tags.
Darauf aufbauend entwickelten die Wissenschaftler eine Art Vorhersagemodell für das Tagging-Verhalten von Nutzern.
|
|
Der Artikel "Semiotic dynamics and collaborative tagging" von Ciro Cattuto, Vittorio Loreto und Luciano Pietronero ist als Online-Publikation der Fachzeitschrift "Proceedings of the National Academy of Sciences" (22.-26. Jänner 2007, doi: 10.1073/pnas.0610487104) erschienen. |
|
|
 Abstract (sobald online) Abstract (sobald online) |
|
|
|
|
|
|
Tagging als Navigationshilfe |
|
| |
Das "Collaborative Tagging" hilft Ordnung zu schaffen und den Überblick zu bewahren: Nutzer organisieren und durchsuchen nach den vergebenen Stichwörtern ihre Internetquellen und lassen - falls erwünscht - auch andere Nutzer über die Stichworte ihr Material sichten. Die einzelnen Tags, also Begriffe, können dabei von demjenigen, der den Inhalt liefert, frei erfunden und vergeben werden.
Diese Art von Kategorisierung ist quasi eine Navigationshilfe. Sie lässt Sammlungen von Lesezeichnen erschließen und durchstöbern, wie etwa auf der Website
del.icio.us der Fall. Oder sie ermöglicht beispielsweise das Finden von Fotos auf Flickr.
|
|
|
|
|
|
Zufällige Vergabe - häufig gleich |
|
| |
Die Stichwortvergabe erfolgt also "durch die Leute", wird so auch als Folksonomy (engl. folks = Leute, taxonomy = Klassifikation) bezeichnet. Es gibt keinen zentralen Koordinator, der die vergebenen Tags bestimmt, überprüft oder besonders hervorhebt.
Auch wenn jeder User - auf Grundlage seiner eigenen Überlegungen - seine Internetdatei frei etikettieren kann, so gibt es doch - wenig verwunderlich - Tags, die besonders häufig verwendet werden.
Wie die scheinbar zufällig ausgesuchten Tags an Popularität gewinnen - oder eben verlieren -, war der Untersuchungsgegenstand der Physiker um Cattuto. Sie nutzten dazu hauptsächlich Daten der Tagging-Seite del.icio.us.
Die Wissenschaftler entwickelten ein einfaches Modell für das Verhalten eines "durchschnittlichen" Internetnutzers. Der Entwicklung ging eine Analyse von Tagging-Daten voraus, um Häufigkeiten des Auftretens eines bestimmten Tags und die Verteilung von anderen Tags, die häufig mit diesem assoziiert sind, zu erfassen.
|
|
|
|
|
|
Die "Tag-Wolke": Je populärer, desto größer
|
|
| |

"Tag-Clouds" sind dabei eine beliebte Visualisierungsmöglichkeiten, die dem Nutzer über die Schriftgröße verraten, welche Tags - im Vergleich zu anderen - häufiger verwendet werden.
Die Annahme von Cattuto und seinem Team für ihr Modell: Je häufiger ein Tag verwendet wird, desto wahrscheinlicher ist es, dass andere Nutzer auch auf diesen Tag zurückgreifen.
|
|
|
|
|
|
Statistische Häufigkeiten |
|
| |
Ein Blick auf die realen Daten verrät: Im Mai 2005 wurde bei del.icio.us der Tag "Blog" - seiner Größe in der Tag-Cloud nach erfreute er sich relativ großer Beliebtheit - genau 37.974 Mal vergeben. Gemeinsam mit "Blog" traten insgesamt rund 24.171 andere Tags (Ko-Tags) auf, dabei 10.617, die eine eindeutigere Beziehung zum Tag "Blog" hatten.
Der Tag "Ajax" - steht für Asynchronous JavaScript and XML und beschreibt eine Technologie der Datenübertragung - wurde ganze 33.140 gepostet (mit 108.181 Ko-Tags, 4.141 davon eindeutig).
|
|
|
|
|
|
Tagging-Aktivität verfolgt: Real und experimentell
|
|
| |
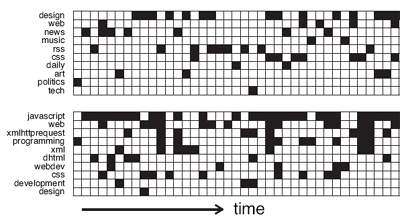
Auf Grundlage der erhobenen Daten stellten die Wissenschaftler die Tagging-Aktivität experimentell auf einer Zeitachse nach: Sie listeten die zehn häufigsten Ko-Tags auf, die u.a. mit dem Tag "Blog" (oberer Balken) und dem Tag "Ajax" (unterer Balken) auftraten.
Jede Spalte symbolisiert dabei ein Tagging-Event, jede Zeile ist einem der Ko-Tags von "Blog" und "Ajax" zugeordnet. Ein schwarz ausgefüllter Kasten markiert, dass der Ko-Tag gesetzt wurde.
Dabei zeigt sich ein qualitativer Unterschied bei den zwei Tags "Blog" und "Ajax", schreiben die Wissenschaftler. Dadurch, dass "Ajax" ein semantisch eingegrenzterer Begriff sei, gebe es eine höhere Dichte bei den Ko-Tags.
|
|
|
|
|
|
Häufigkeitsrang-Verteilungen |
|
| |
Die Wissenschaftler entwickelten zudem Häufigkeitsrang-Verteilungen für die Ko-Tags von "Blog" und "Ajax". Die Kurven folgten einem Verhalten nach dem Potenzgesetz (engl. Power Law).
Bei dem Eintrag "Blog" gab es einen flacheren Kurvenverlauf. Das kann laut der Forscher daher kommen, dass es andere, semantisch gleichbedeutende Begriffe gibt (etwa "Blogs"), die um die Ko-Tags konkurrieren. Zudem: Je genereller die Tags - semantisch gesehen - angelegt sind, desto größer sei die Anzahl der zu erwartenden Ko-Tags (flacherer Kurvenverlauf). Bei dem semantisch eng gefassten Begriff "Ajax" wäre die Kurve steiler verlaufen.
Um ihrem Modell eine Art "Langzeit-Gedächtnis" beizufügen, adaptierten die Wissenschaftler ein so genanntes Yule-Simon-Modell. Die "zeitliche Ordnung" der Ko-Tags wurde nun berücksichtigt - damit Wahrscheinlichkeiten, wann User einen neuen Tag einführen oder alte - bereits vorhandene - einfach kopieren.
Die Annahme der Wissenschaftler: Ein Tag jüngeren Alters würde eher wieder verwendet als ein Tag, der bereits sehr alt ist.
|
|
|
|
|
|
Ähnliches Nutzerverhalten |
|
| |
Die mit Hilfe des entwickelten Modells ermittelten Ergebnisse des Nutzerverhaltens beim Tagging entsprachen relativ gut der Wirklichkeit. Die Schlussfolgerung der Physiker: Trotz individuellem Ordnungssinn - ohne einen koordinierenden "Ordnungschef" - und eigener Stichwortvergabe der User ist die Vergabepraxis der Begriffe bei allen Nutzern sehr ähnlich.
Die Wissenschaftler gehen davon aus, dass ihre Ergebnisse klären können, wie gemeinschaftliche Kategorisierungen und einzelne Vokabeln in einem komplexen System mit Tausenden von Nutzern aufkommen können.
Lena Yadlapalli, science.ORF.at, 23.1.07
|
|
|
01.01.2010 |
