 |
|
|
|
|
|
 |
 |
Neues aus der Welt der Wissenschaft |
|
|
|
|
|
|
Rauschfreie Sprachübertragung dank Chaostheorie |
|
| | | Wenn Sprache technisch verarbeitet und übertragen wird, kann Rauschen zu einem erheblichen Störfaktor werden. Mit Hilfe eines neu entwickelten Verfahrens, das auf der Chaostheorie basiert, kann beispielsweise rauschfreies Telefonieren aber bald möglich werden. Besonders gut eignet sich das Verfahren laut seinen Entwicklern jedoch als Vorstufe für automatische Spracherkennungssysteme. |
|
|
|
|
|
|
|
|
| |
Das System filtert Rauschen auch dann sehr effektiv heraus, wenn es zeitlich stark schwankt. Gerade die ständige und sprunghafte Veränderung von Hintergrundgeräuschen lässt die üblichen Verfahren zur Rauschunterdrückung an die Grenzen ihrer Möglichkeiten stoßen.
Für das von Holger Kantz und seinen Mitarbeitern am Max-Planck-Institut für Physik komplexer Systeme entwickelte Verfahren stellt diese Variable kein Problem dar. Es führt allerdings zu einer Verzögerung bei der Übertragung des Sprechsignals und eignet sich deshalb vor allem für die automatische Spracherkennung, da die zeitliche Verzögerung beim Telefonieren störend sein kann.
Die Wissenschaftler stellen ihre Methode in der neuesten Ausgabe des Wissenschaftsmagazins "MaxPlanckForschung" (2/2003) vor.
|
|
|
|
|
|
Leicht zu mischen - schwer zu trennen |
|
| |
Rauschen steckt immer schon im Eingangssignal, das technische Kommunikationssysteme weiter verarbeiten müssen - sei es ein Handy oder ein Sprachcomputer für das Telefon-Banking. In diesem Eingangssignal überlagert das Rauschen als Störsignal das Nutzsignal der Sprache.
Diese beiden Signalanteile verhalten sich wie zwei Farben: Es ist leicht, beide zu mischen - doch extrem schwer, sie danach wieder zu trennen. Genau das muss ein Rauschunterdrückungssystem aber schaffen.
|
|
|
|
|
|
Unbekannte Signale |
|
| |
Beim Kassettenrekorder lässt sich das Problem noch leicht lösen, denn ein Magnetband rauscht monoton. Die Ingenieure müssen das Rauschsignal nur einmal im Labor ausmessen und können dann ihr System darauf optimieren.
Völlig anders ist die Situation bei der Sprachübertragung im Alltag: Der Sprecher kann sich in einer lärmenden Fabrikhalle oder in einem stillen Wald aufhalten. Also muss das System ein Rauschsignal bekämpfen, das es nicht von vornherein kennt und das sich sehr plötzlich ändern kann. Solche unvorhersehbaren Signale sind schwer zu beherrschen - Physiker nennen sie "nicht-deterministisch".
|
|
Die gängige Methode der Rauschunterdrückung
Die Methoden, die heute in der Telefonie, bei Hörgeräten oder in der automatischen Spracherkennung Verbreitung finden, beruhen auf Erfahrungswerten und ziehen einfach ein durchschnittliches, breitbandiges Rauschen vom Gesamtsignal ab.
Diese starre Filterfunktion kommt an ihre Grenzen, sobald sich die Charakteristik des Rauschens während des Sprechens stark verändert - etwa dann, wenn ein Autofahrer eine Panne hat und neben einer viel befahrenen Straße mit seinem Handy den Pannendienst anruft: Der Gesprächspartner hört die vorbeifahrenden Autos als stark an- und wieder abschwellendes Rauschen. |
|
|
|
|
|
|
Die Addition von Signalen |
|
| |
Solche Situationen beherrscht das flexible Verfahren der Dresdener Physiker. Holger Kantz erklärt das Grundprinzip an einem Beispiel: "Stellen Sie sich vor, Sie hätten mehrere Exemplare einer klassischen Vinyl-Schallplatte mit exakt der gleichen Information darauf und jede dieser Schallplatten hätte an unterschiedlichen Stellen Kratzer oder andere Fehler, die für individuelle Störsignale sorgen."
Würde man nun alle Schallplatten zum exakt gleichen Zeitpunkt starten und ihre Signale überlagern, würde Folgendes passieren: Die eigentliche Information - ob Sprache oder Musik - würde sich addieren, also verstärken. Anders wäre das beim Rauschen, dessen Signale von Platte zu Platte zufällig variieren und sich deshalb nicht konstruktiv überlagern. Mittelt man nun das addierte Signal, würde der Rauschpegel mit einer wachsenden Zahl von Schallplatten sinken.
Bei Freisprechanlagen in Autos übernehmen mehrere Mikrophone die Rolle der Schalplatten. Handys und viele andere Systeme arbeiten jedoch nur mit einem Mikro. Daher kommt diese Lösung für sie auch nicht in Frage.
|
|
|
|
|
|
Signale aus der Vergangenheit |
|
| |
Um dieses Problem zu knacken, wenden die Wissenschaftler die Theorie des "deterministischen Chaos" an. Sie gestattet, in Systemen mit scheinbar rein chaotischem Verhalten wiederkehrende Strukturen aufzudecken.
Die Forscher fragten sich, ob es auf der Zeitachse des Sprachflusses zu einem gerade produzierten Signal ein zweites in der Vergangenheit gibt, das dem ersten stark ähnelt:
Ein solches "redundantes" Signal könnte dann die Rolle der zweiten Schallplatte übernehmen, also dem eben eingetroffenen Signal überlagert werden und so den Rauschpegel halbieren. Mit weiteren redundanten Signalen aus der Vergangenheit ließe sich der Rauschpegel sogar noch tiefer drücken.
|
|
|
|
|
|
Das Problem der Verzögerung |
|
| |
Um dabei die Übertragung nicht zu lange zu verzögern, sucht das Dresdener Verfahren nur die sehr nahe Vergangenheit nach vergleichbaren Mustern ab. Dafür geeignete Zeitabschnitte bieten die Laute, aus denen wir Worte formen. Das Aussprechen eines solchen Phonems dauert in der Regel nicht länger als 200 Millisekunden (eine Fünftelsekunde).
Den Schlüssel für ihren Algorithmus fanden Kantz und seine Mitarbeiter in Vokalen und stimmhaften Konsonanten; beide bilden erstaunlich gleichmäßige Schwingungsmuster, die über viele Millisekunden hinweg stabil sind.
|
|
|
|
|
|
Stabile Schwingungsmuster bei "i" und "j"
|
|
| |
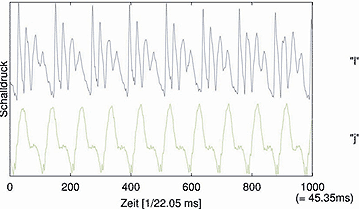
Die zwei verschiedenen Phoneme "i" und "j" weisen erstaunlich stabile Schwingungsmuster auf. Der gezeigte Zeitausschnitt entspricht etwa 45 Millisekunden.
Die Messkurve zeigt, wie gut sich die Wellen in so einem Phonem wiederholen," sagt Holger Kantz. Das erlaube es dem Algorithmus, einen typischen Wellenzug aufzunehmen und dann auf der Zeitachse rückwärts zu verschieben:
Immer dann, wenn er mit einem früheren weitgehend übereinstimmt, entsteht ein maximales Signal. Übereinander gelagert, können diese vergleichbaren Abschnitte die Aufgabe der zwei Schallplatten übernehmen.
|
|
|
|
|
|
Auf der Suche nach Ähnlichkeiten |
|
| |
Die Dresdener Physiker untersuchten zunächst Signale ohne Störung, um zu sehen, ob ihr System überhaupt solche Signalwiederholungen aufspüren kann. Dabei half ihnen ein so genannter Rekurrenzplot. Das ist eine Art Landkarte für Sprachsignale, wie sie das nächste Bild zeigt: Im oberen Fenster sieht man das Sprachsignal als physikalische Schwingung.
Interessant ist das "Zebramuster" im unteren Fenster des Plots. Was völlig abstrakt aussieht, ist im Prinzip einfach zu verstehen: Von links nach rechts schreitet die Zeit im gleichen Takt wie im oberen Fenster voran. Bewegt man sich im Plot senkrecht zu dieser Zeitachse, folgt man der wachsenden zeitlichen Verschiebung eines herausgegriffenen Wellenzugs.
Immer dann, wenn dieser sich einem sehr ähnlichen Wellenzug in der Vergangenheit überlagert, macht das System einen Punkt im Rekurrenzplot. Die Muster zeigen damit die Ausdehnung eines Phonems: Wo sich viele Punkte übereinander türmen, gibt es viele ähnliche Wellen.
|
|
|
|
|
|
|
|
| |
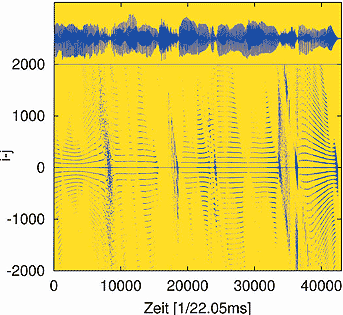
Um nun ihr neues System zu testen, mischte die Gruppe um Kantz Rauschen in das saubere Sprachsignal. Obwohl das verrauschte Signal physikalisch völlig verändert war, zeigte sich, dass der Rauschunterdrückungs-Algorithmus tatsächlich ähnliche Wellenzüge zuverlässig aufspürt und das ursprüngliche Sprachsignal erstaunlich gut aus dem Frequenzchaos herausfiltert.
|
|
|
|
|
|
Extrem leistungsfähig, mit kleinen Fehlern |
|
| |
Weitere Vergleichsmessungen haben nach Angaben der Forscher bewiesen, dass das Dresdener System auf Anhieb mit den modernsten Rauschunterdrückungs-Algorithmen mithalten kann. Weitere Optimierung könnte demnach die Leistungsfähigkeit des Verfahrens noch erheblich steigern.
Allerdings hat es auch einen Nachteil: Der Vergleich mit der Vergangenheit verzögert die Übertragung des Sprechsignals um ein Phonem, also etwa um eine Fünftelsekunde. Beim Telefonieren kann das stören.
Aus diesem Grund eignet sich das Verfahren vor allem für die automatische Spracherkennung und könnte dort eine weitere Stärke ausspielen: die Fähigkeit, Grenzen einzelner Phoneme sehr scharf zu erkennen. Damit haben die Algorithmen heutiger Spracherkennungssysteme große Schwierigkeiten.
|
|
|
01.01.2010 |
